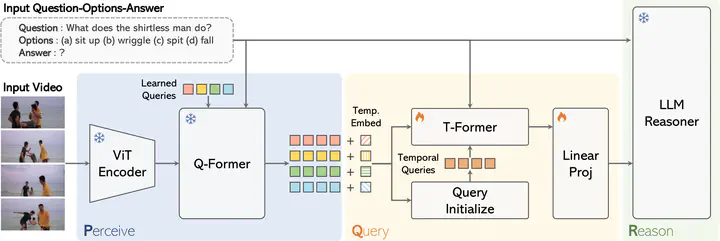
 Overview of our proposed PQR (Perceive, Query, and Reason) architecture.
Overview of our proposed PQR (Perceive, Query, and Reason) architecture.Abstract
Video Question Answering (Video QA) is a challenging video understanding task that requires models to comprehend entire videos, identify the most relevant information based on contextual cues from a given question, and reason accurately to provide answers. Recent advancements in Multimodal Large Language Models (MLLMs) have transformed video QA by leveraging their exceptional commonsense reasoning capabilities. This progress is largely driven by the effective alignment between visual data and the language space of MLLMs. However, for video QA, an additional space-time alignment poses a considerable challenge for extracting question-relevant information across frames. In this work, we investigate diverse temporal modeling techniques to integrate with MLLMs, aiming to achieve question-guided temporal modeling that leverages pre-trained visual and textual alignment in MLLMs. We propose T-Former, a novel temporal modeling method that creates a question-guided temporal bridge between frame-wise visual perception and the reasoning capabilities of LLMs. Our evaluation across multiple video QA benchmarks demonstrates that T-Former competes favorably with existing temporal modeling approaches and aligns with recent advancements in video QA.
Roberto Amoroso
ELLIS PhD | AI & Computer Vision
International Doctorate in ICT
My research interests include Open-vocabulary Image Segmentation and Multimodal Video Understanding.